

Over the past few years, voice assistants have penetrated our daily lives. We all walk around with a personal butler whether it’s named Siri, Google Now or Samsung Bixby. These little friends have found their way into our homes through devices such as Amazon Echo and Google Home.
Whereas voice assistants were considered playful gadgets only a few years ago, recent advances in machine learning have propelled them into useful time-savers that help us schedule meetings, answer emails, construct shopping lists and answer questions in a reliable way.
While these basic problem-solving skills are fueling rapid adoption the real promise of the technology is much larger. Voice should be the most natural way for us to interact with most technologies that surround us. But for this to happen voice assistants need to develop the ability to sustain conversations, not simply respond to basic questions. This is why they need to become much better at understanding the individuals they communicate with and more specifically their context.
Context matters in conversations
Context plays at 3 levels in conversations:
- The conversation itself. Context is built within conversations from the first exchange. Previous exchanges within the conversation establish important context to determine future interactions.
- The environment. Where I am, what others around me are doing and perhaps expect from me, the weather, noise level, etc. are all also important.
- The person you are talking to. What I am doing right now, was doing earlier, am planning to do next determines what conversations I am open to and how I would like them to go.
Most people understand context at these levels very intuitively. Digital voice assistants are trying to catch up. While advances have already been made in understanding the context of the conversation itself as well as the environment, most technologies still only incorporate a very rudimentary view of the user’s context. In what follows we will describe how voice assistants can learn the user’s context to make conversations more natural. In order to do so, let’s first look at how voice assistants work today.
How voice assistants work today
Voice assistants are really just intelligent chatbots with a speech recognition and speech synthesis layer on top of them. Although speech recognition, understanding, and synthesis are extremely challenging fields of research, recent advances have resulted in algorithms that come close to human performance on both recognition and synthesis.
If we ignore speech technology for a moment and focus on the chat-bot component of the assistant, it becomes clear that most solutions use one of two models:
- Retrieval-based: These models use advanced machine learning techniques to select an appropriate response from a large set of predefined answers. Most commercial grade virtual assistants are retrieval-based methods.
- Generative: These models generally use deep learning to generate responses on the fly, allowing for a much more dynamic and natural range of responses and showing the ability to cope with unexpected input. However, as there is no absolute guarantee for grammatical correctness and semantic consistency of the responses, this approach is mostly of interest to the academic research community these days.
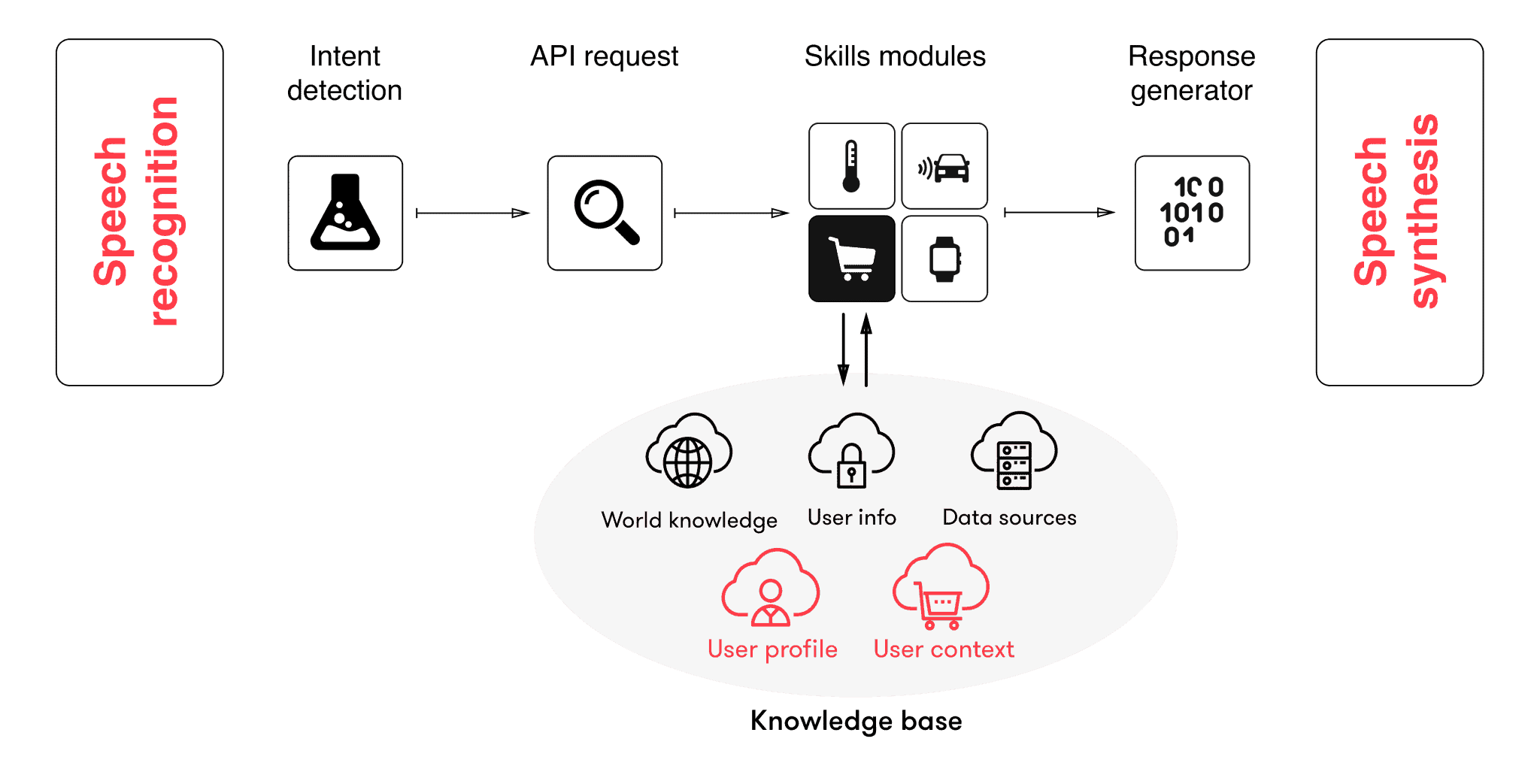
To select an appropriate response to a user query, the chatbot contains an intent detection module that translates the question of the user into an API request to a specific skill module. Skill modules could be focused on weather forecasts, traffic information, calendar interaction, etc. This is illustrated by the figure below:

Once the request arrives at the right skills module, this module is able to interrogate a knowledge base, consisting of a world view (e.g. information on the user population), some user info (e.g. the user’s settings or past requests) and potentially a set of external data sources (e.g. geographic information systems).
The skills module performs the necessary computations and combines the data it needs to generate a meaningful output, which is passed to the response generator. The response generator translates the resulting knowledge back into natural language, which is then synthesized into speech.
The problem with the above approach is two-fold:
- Knowledge bases are either static, or only change based on previous user requests, thereby completely ignoring the user’s activities, goals, personality and current state of mind.
- The intent detector is unaware of the user’s current context, thereby generating the same response to every user that formulates the same query. However, if a user asks about pricing information on a certain product, then the users’ intent might be very different if the question is asked during his weekly shopping routine versus during a lazy Saturday at home.
Understanding motion to build context-aware voice assistants
So how can we detect the user’s context in real-time? Smartphones can be very useful here, especially for analyzing the user’s physical movement. The vibration of the phone sensors, for example, is very different if you’re on a train or in a car. This is how Sentiance’s motion-based intelligence platform detects and predicts a user’s context in real-time. Their commute, the places they visit, their daily routines, when they walk the dog, drop off their kids, ... - every moment throughout their day determines how they should be communicated with.
So how can understanding the moments in a user’s day make voice assistants better? This is illustrated in the figure below:
By providing information on the user’s moments and deriving their personality, state-of-mind and real-life intent, both the skills modules and the query intent detector can personalize their logic to the user’s need.
Let’s make this more concrete with an example. Imagine two users asking the following question:
Query: “What is the price of a Basic Fit gym subscription?”
Now imagine Sentiance detecting the following state for these two users:
User 1:
Segments: athletic, business person, work traveler
Moments: business trip, sporting
Predictions: going back to the hotel in 1 hour
User 2:
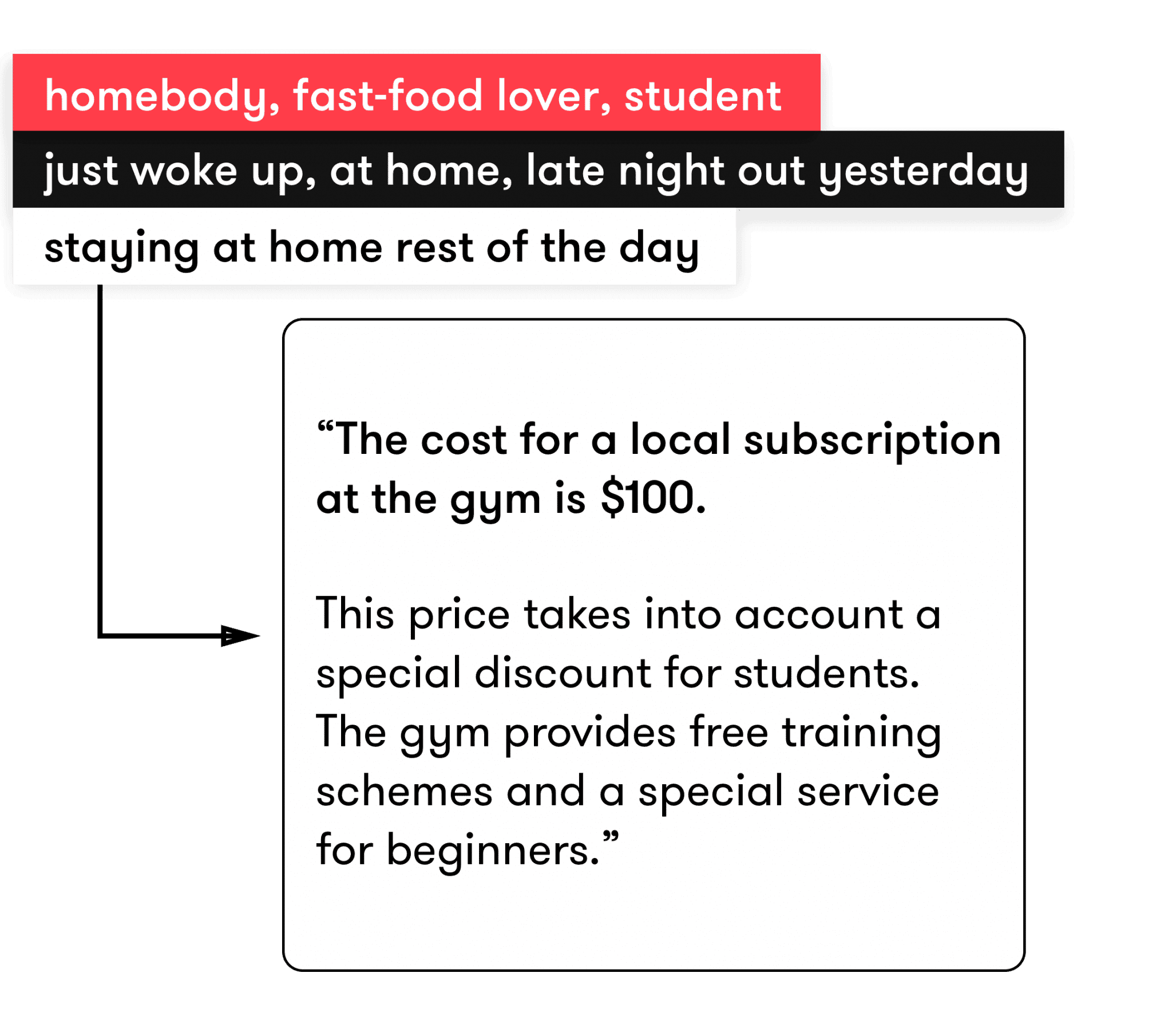
Segments: homebody, fast-food lover, student
Moments: just woke up, at home, late night out yesterday
Predictions: staying at home the rest of the day
Instead of simply generating the same response to these two users, a virtual assistant should tailor its responses to the user’s needs and state of mind. For example:
Response to user 1: “The cost for a worldwide subscription is $150. If you subscribe now, you can immediately use it for the gym you are currently visiting, but note that this gym closes in 15 minutes. There is a 24/7 fitness center you can visit just around the block.”

Response to user 2: “The cost for a local subscription is $100 taking into account a special discount for students. The gym provides free training schemes and a special service for beginners.
These examples only scratch the surface but they clearly show how our machine learning technology enables virtual assistants to detect user intent in a personal way and to use the user’s context and personality to formulate answers.
We believe Sentiance’s unique motion-based intelligence platform provides an indispensable AI layer for any voice assistant that wants to become truly context-aware. Without knowing a user’s real-time and predicted context assistants will never fully understand who the user is, why they are doing the things they are doing, and what their next action is expected to be. Anyone who has spent time dealing with customers face to face would agree these are the foundational insights behind any successful customer interaction. If voice assistants want to conquer the world, they’d better start getting this foundation right.





