
Introduction
Our virtual lives lie in the hands of algorithms that govern what we see and don’t see, how we perceive the world and which life choices we make. Artificial intelligence decides which movies are of interest to you, how your social media feeds should look like, and which advertisements have the highest likelihood of convincing you. These algorithms are either controlled by corporations or by governments, each of which tend to have goals that differ from the individual’s objectives.
In this article, we dive into the world of human-centric AI, leading to a new era where the individual not only controls the data, but also steers the algorithms to ensure fairness, privacy and trust. Breaking free from filter bubbles and detrimental echo chambers that skew the individual’s worldview allows the user to truly benefit from today’s AI revolution.
While the devil is in the implementation and many open questions still remain, the main purpose of this think piece is to spark a discussion and lay out a vision of how AI can be employed in a human-centric way.
How machines learn: The value of morality and ethics
Training an AI model requires two components: training data and a reward or cost function. During the training phase, a model learns how to obtain the maximum reward, or minimum cost, by acting on the data it is fed.
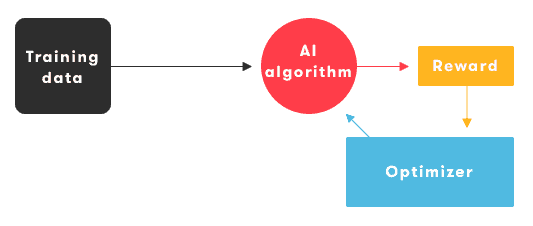
Figure 1: Training cycle of a machine learning model
For example, in the field of face recognition, the reward can be defined to be proportional to the number of faces correctly classified by the model. After several training iterations, the optimizer then fine-tunes the internals of the AI algorithm to maximize its accuracy.
So how does this compare to the human learning process? As opposed to algorithms, humans are not completely rational. We tend to learn, and teach, in a much more complicated environment, where our reward function is influenced heavily by laws, ethics, morality and societal norms.
The fact that these principles are unknown to an AI algorithm, can cause it to completely disregard important factors such as ‘fairness’ during training, as long as its reward is maximized. In the field of reinforcement learning and game-theory, for example, it has been shown that AI models often learn to cheat or cut corners, in order to reach the highest reward as fast as possible.
A rational agent should choose the action that maximizes the agent’s expected utility
—Russell and Norvig
Artificial Intelligence: A Modern Approach
Extrapolating this to real-world applications of AI poses some interesting questions. What happens when an AI algorithm is taught to show content to its users if we simply use ‘click-through rate’ as a reward? Will the algorithm show content that benefits the user in the long run, or will it simply learn to select content that elicits the most reactions, optimizes for likes, and provokes emotional responses?
Indeed, this is exactly the danger of modern recommendation engines used in social media platforms, search engines, and entertainment frameworks. Deep neural networks implicitly learn to model underlying cognitive factors that cause users to engage with content. Driven by its ill-defined rewards function, the algorithm focuses on short-term gain without regard of the user’s long-term goals or its implications on the user’s worldview.
If based on cognitive profiling and psychometrics, this is often referred to as persuasion profiling, where the main goal is to trigger the user to behave in a specific way, thereby placing the needs of the strategist above the needs of the user.
Towards trustworthy Artificial Intelligence
The premise of human-centric AI is a strong conviction that artificial intelligence should serve humanity and the common good while enforcing fundamental rights such as privacy, equality, fairness and democracy.
However, people can only reap the full benefits of AI if they can confidently trust that the algorithm was taught to serve their interests as opposed to those of a third-party institution or corporation. For example, instead of optimizing a recommendation engine to maximize the number of impressions, one might choose to maximize the quality of impressions.
The reward to be optimized should be aligned with the user’s goals. For example, a user might be highly likely to click on a message that promotes fast food, when presented. Yet, a human-centric AI engine should take into account the user’s goals related to weight-loss or health before recommending that message to the user merely for the sake of increasing click-through rate.
Thus, in an ethics-by-design framework, it is the algorithm creator’s responsibility to design the AI to only engage if an overlap can be found between the individual’s personal goals, the company goals and potential third-party (e.g. brands, sponsors or clients) goals.
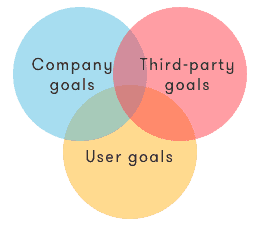
Figure 2: Trustworthy AI is human-centric, thereby putting the user's interest first, while searching for overlap with company goals.
By doing so, the AI acts as a ranking and prioritization filter, not only providing and recommending the next best thing for a user, but also filtering out anything that will be counterproductive in achieving the user’s goals, e.g. unwanted noise or spam.
Making sure that the user’s goals are understood and taken into account correctly requires some fundamental changes in how data is treated and how algorithms operate. The ability to give users complete control over both data and logic depends heavily on the provisioning of technical tools related to explainability of decisions, traceability of data flows, and curation of data and digital identity on the one hand, and an algorithmic focus on intent modeling, personalization and contextualization on the other hand.
A user-centric data paradigm
Most AI applications today result in a so called inverse privacy situation. Personal information is inversely private if only a third party has access to it while the user does not. Inversely private information ranges from historic user declared data which the user does not have access to anymore, to inferred and derived data that was generated by algorithms.
While inversely private data is often used by companies to improve the user’s experience, shielding it from the user makes it impossible to correct wrongly derived information, or to delete data points that the user does not deem appropriate to be shared anymore at a certain point in time.
In a user-centric data paradigm, this unjustified inaccessibility is eliminated completely by ensuring the user has access to all information known about him or her, in a convenient and interpretable manner. Moreover, data is considered fluid, such that something shared by a user at some time, can be retracted or changed at any time in the future.

Figure 3: Inversely private data is personal information that is only accessible by a third-party.
This user-centric data fundament naturally leads to the concept of zero-party data. While first-party data represents data that is gathered through a company-initiated pull mechanism (‘ask’), zero-party data is personal information that is obtained through a user-initiated push mechanism (‘provide’) accompanied with clear restrictions on what the data can be used for.
An example of first-party data could be demographic information of a user, asked when the user subscribes to a service and used for the benefit of the company. An example of zero-party data, on the other hand, could be the user’s preferences, interests or goals, voluntarily provided by the user, with the explicit agreement that this data will only be used for the benefit of this user.

Figure 4: Zero-party data is personal information provided by the user with the implicit contract that the data will only be used to improve the user's experience.
The use of zero-party data, combined with the elimination of inversely private data, leads to bi-directional full transparency which is crucial to build a trust-relationship. Moreover, it allows the user to take the initiative to improve the algorithm by solving algorithmic bias caused by data partiality.
However, to move towards a fully trusted relationship, it is not enough to just give the user control over his or her data. It is as important to provide the user with full historic traceability of who accessed the data and for which purpose.
Imagine the case where a user provides a data point to company A, which in turn derives analytics that are used by company B, after which companies C and D uses it to personalize their respective services. In a user-centric data agreement, company A ensures that each of those transactions is logged and visible to the user.
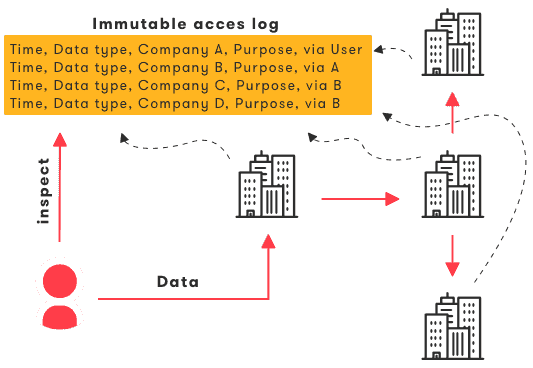
Figure 5: Full traceability of data usage, consumer identification and purpose enforce trust and transparency.
The user might then change, augment or complete his or her data, or even restrict future access for specific purposes or by specific companies through a data configuration portal from company A. Technologies such as linked hash chains or blockchain based distributed ledgers can provide immutability and traceability of access logs to prevent fraud while guaranteeing privacy.
The user-centric data paradigm therefore transforms the traditional one-direction funnel into a trusted and mutually beneficial partnership between user and brand through transparency, ownership and a change of control.
The algorithm of you
The user-centric data paradigm enforces trustworthiness but does not guarantee the human-centric application of AI in itself. Human-centric AI is based on the idea that AI should be used to help individuals reach their goals as opposed to using company business metrics as an optimizable reward.
To make this possible, the algorithm needs to be informed about the user’s goals in some way. Although long-term goals and mid-term goals could be provided by the user explicitly as zero-party data, short-term goals, i.e. intent, are often too short-lived.
Thus, a crucial component of human centric AI, is intent modeling: Using AI to estimate the user’s short-term goals in a personalized and contextualized manner. For example, if a user is currently in a car, then whether his or her short-term intent is ‘commuting to work’ or ‘dropping of the kids at day-care’ can make a huge difference on how a music recommender should operate.
The combination of zero-party data with intent modeling and contextualization leads to a virtual persona reflecting the user’s digital identity. It’s exactly this idea that was coined the algorithm of you by Fatemeh Khatibloo, Principal Analyst at Forrester in 2018: Modeling a personal digital twin within the constrained framework defined by the user-centric data paradigm.
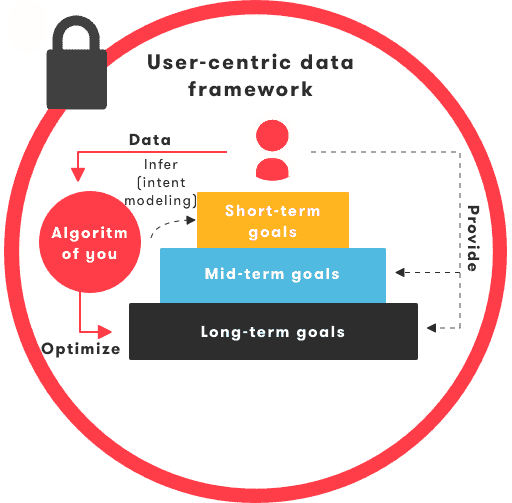
Figure 6: The 'Algorithm of You' refers to a highly personalized and contextualized algorithm that operates within the user-centric data paradigm, and that is under complete control of the user.
Having a personal digital twin allows the user to enforce curation of identity by configuring how the digital twin behaves when interrogated by companies. In real-life, we rarely hand out the same information to strangers as we do to friends. Similarly, parts of a user’s digital twin should only be exposed to trusted brands or for specific purposes, while others might be exposed to everyone.
Trustworthiness is thus guaranteed by enabling the user to steer the behavior of the algorithms by changing, removing, augmenting or hiding parts of the digital twin’s DNA, thereby effectively providing a curated version of his or her identity to different institutions or for different purposes.
A key consideration that is necessary for the user to be able to configure his or her digital twin, is automated explainability and interpretability of the AI’s decision making. By explaining the user why certain actions are taken or which data points lead to specific recommendations, he or she is able to judge whether or not the data is used in an appropriate manner that contributes to the user’s goals.
Your personal digital twin
The concept of a personal digital twin embodies the idea of capturing the user’s mindset, lifestyle, and intent in a digital manner, such that it can be interrogated by an AI model. Although the user-centric data paradigm enables the user to curate, edit and enrich this digital identity, it would be cumbersome for the user to have to constantly refine this profile manually. A baseline user profile therefore needs to be detected and updated automatically and in real-time.
To obtain his or her digital identity in an automated manner, a user can enable the algorithm of you to observe his or her day-to-day behavior continuously, thereby extracting meaningful patterns, routines, profile and personality insights, and predictions. Automatically detecting low-level user motion (e.g. walked three steps) and turning those activities into high-level contextual insights (e.g. walking the dog while being late for work) requires advanced AI capabilities that act as multi-resolution pattern detectors on the underlying data. But where would a user find data that is fine-grained enough to unlock such capabilities?
We all run around with a smart phone almost 24/7, to the extent that a smart phone could be considered an extension of our body, albeit a physically disconnected one. So how can we leverage the power of smart phone sensors to bridge that physical disconnect and thus track motion, movement and orientation? Our brain uses a process called proprioception to obtain a continuous sense of self-movement and body position based on sensory activations in muscles, tendons and joints which are integrated by the central nervous system.
Can we emulate this process virtually, in order to give our personal digital twin the ability to sense motion, orientation and position? Smart phones are packed with high resolution proprioceptive sensors such as accelerometers, measuring every small vibration, and gyroscopes which track orientation changes. Integrating those sensors, in a process called sensor fusion allows an AI model to estimate and detect user activities.

Figure 7: Proprioceptive sensor fusion allows the AI model to obtain a sense of self-movement and motion of the smart phone which acts as a digital proxy for the human body.
Examples of low-level activities, also called events, that could be recognized by the AI model are transport modes when the user is on the move (e.g. walking, biking, driving, train, etc.), venue types when the user is stationary (e.g. home, work, shop, etc.), and fine-grained driving style insights when the user is driving or gait analysis when the user is walking. A temporal sequence of those activities makes up a user’s event timeline:

Figure 8: The ordered sequence of detected events makes up a user's behavioral timeline.
This event timeline explains what the user is doing, but doesn’t reveal intent yet, as needed by the algorithm of you in the human-centric AI framework. However, by detecting patterns and routines in this timeline, a predictive model can start predicting the user’s next actions, which in turn leads to explanation of intent. For example, if the user was observed to be at home, is currently in a car, and is predicted to arrive at work soon, then the intent of this particular car trip is ‘commute to work’.
Intents, such as commute, kids drop-off, sport routine or business trip, can therefore be considered a short-term aggregation of the underlying activity timeline, enriched with detected patterns and anomalies. This is what Sentiance refers to as moments which are designed to explain why the user is doing something instead of only what the user is doing.
Aggregating events (‘what’), moments (‘why’) and predictions (‘when’) over even longer periods of time then allows the AI model to put those events and intents into the perspective of who the user is. What is the user’s cognitive state? What are his or her long-term patterns? Is this user working out today by chance, or is he or she a sportive person in general?
The long-term view on the user’s personality and traits is what we call segment detection. Segments tend to explain who the user is, apart from just what he or she is doing and why.
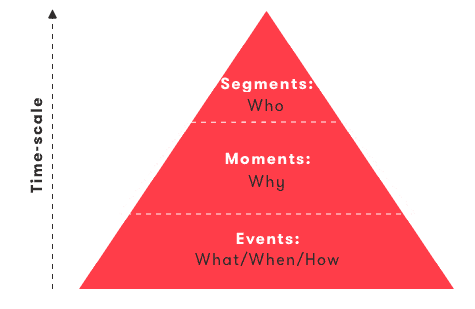
Figure 9: Aggregating behavioral events over different time-scales allows the algorithm of you to model contextualize and understand the user's actions, intents and goals.
Apart from proprioceptive sensors, the user can request the AI model to ingest zero-party data, or specific data points such as in-app behavior, that can further deepen and strengthen the user’s digital identity. This allows the personal digital twin to bridge the gap between on-line and off-line behavior.
This type of contextualization results in a digital identity that the user can use to enable highly personalized experiences, recommendations and services by configuring algorithms to interact with his or her digital twin. The fact that all of this happens within the user-centric data paradigm is a crucial component of the algorithm of you, as it guarantees correctness of the inferred insights, privacy towards the user who acts as data owner, and trust between all parties involved.
Conclusion
Human-centric AI can be achieved by creating a personal digital twin that represents a virtual copy of the individual’s behavior, goals and preferences. Contextualization and intent modeling are crucial to avoid bothering the user too often. At the same time, the individual should be in control of his or her data, and a trust relation should be built by guaranteeing traceability of data access, explainability of the AI’s decisions, and by providing the user with a convenient way to view, edit, control and curate this data.
The algorithm of you builds on the idea that the individual directly controls the inner workings of the algorithms by having the ability to change or enrich his or her data through a data configuration portal. Models should be optimized based on the individual’s goals, while searching for overlap with company or third-party goals.
In this framework, the healthy tension between company goals and user goals is not a zero-sum game. If AI is used in a trustworthy and user-centric manner, the relationship between users and brands completely changes. Suspicion becomes curiosity, persuasion becomes collaboration, and brands and users unite in fandoms centered around trust.


