

Introduction
At Sentiance, we create contextual insights and drive behavioral interventions through our platform. This platform uses AI-powered data analysis techniques to turn raw smartphone sensor data into rich and actionable insights.
Traditionally, we have been developing this technology with a focus on data processing in the Cloud. However, advances in smartphone technology and in Machine Learning toolkits have paved the way for bringing our brand of data processing directly to the smartphone; resulting in a more privacy-sensitive solution without significant battery impact.
Edge computing is the next step in getting to another dimension in Human AI, the Algorithm of You.
In this blog post, we will talk about the WHY and HOW of this massive change.
What is On-Device Data Processing?
When creating any kind of data platform, there are a number of processes that such a platform needs to support:
- Data collection: Capturing the raw data that the data platform has been developed to work with. This could be anything from user-generated input, such as tweets, photos, or video, to sensor data, to documents, and more.
For Sentiance, it consists of sensor data captured from smartphones such as location, accelerometer, and gyroscope data. - Data processing: Actions performed on the collected data to clean it, extract information, transform it into other formats, etc.
For Sentiance, it runs the spectrum of quality checks, to low-level signal processing, to ML-based classification, clustering, and predictions, to rule-based approaches in order to turn a couple of data points into meaningful, human-understandable insights. For example, turning a sequence of sensor measurements into the transport mode someone was using to get from point A to B. - Data enrichment: Merging raw, intermediate, or final results of data processing with other internal or external data sources to increase the information content.
Sentiance uses geospatial databases, weather, and traffic information to augment the data processing. - Data storage: Retaining raw and enriched data for retrieval, backup, or regulatory purposes.
At Sentiance, data is stored in the Cloud on Apache Kafka message queues during processing, in PostgreSQL databases to serve content accessed via APIs, and in S3 for backups. - Data integration: Providing access to data stored within the data platform.
For Sentiance, this means providing access to data and insights that have been generated on behalf of the clients we work with. This data access consists of a GraphQL-based API for pull-based retrieval, a Firehose for push-based messaging, and offloads for bulk ingestion.
As a whole, the Sentiance Platform can be seen as the combination of a Mobile SDK (Android/iOS) and a Cloud backend that take up the processes listed above. Traditionally, the primary purpose of the Mobile SDK has been to perform data collection, with the emphasis lying on the Cloud backend to take care of all the other data processes.
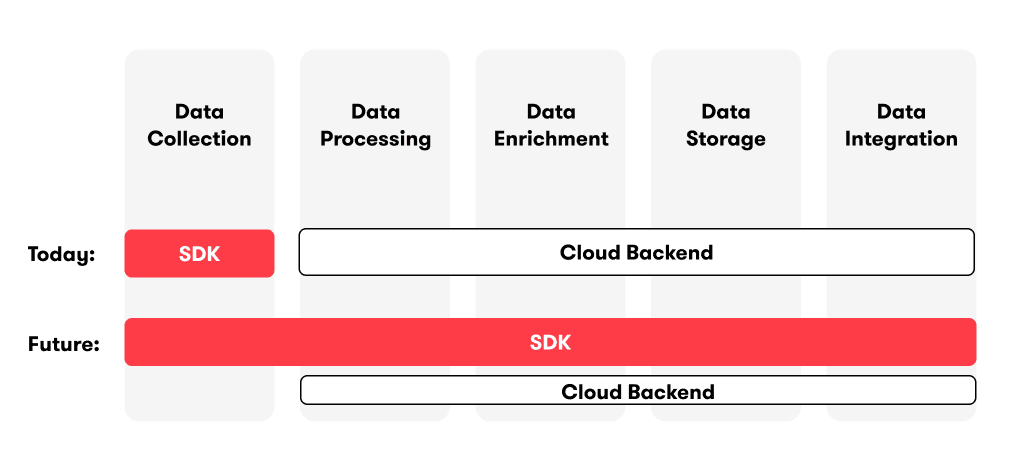
Figure 1: Transitioning data management tasks from Cloud to SDK
On-Device Processing, or edge computing, turns this around and makes the Mobile SDK the central component of the Sentiance Platform, see Figure 1 above, with the Cloud backend taking care of SDK configuration management and authentication, some supporting services (e.g. for geospatial data), reporting, and existing integrations, as well as any data processing that is currently still more appropriate to be performed in the Cloud.
Why go this route?
The decision to take such a drastic change in mindset for the Sentiance Platform did not come overnight, yet there were enough reasons and indicators to evolve our technology in such a way.
Keeping personal data personal
Providing rich insights from smartphone sensors can lead to having to manage sensitive user data, especially precise locations, which are considered personal data. Sentiance has a long history of safely and securely storing this data in its Cloud platform, with many security reviews from our clients to vouch for it. Regardless, it remains a setup that needs constant scrutiny and (security) updates to remain safe which comes with additional costs to development, tooling and operations.
Processing personal data directly on the phone, however, brings a new mode of operation to the table. So instead of bringing the data to our algorithms, we bring our algorithms to the data. By extracting the insights in the same place where the data is generated, neither the personal data nor the insight still need to leave the device. While some data might still be synced to the Cloud, for example for debugging or reporting purposes, it can be cleansed of any identifying information.
A more resource-conscious solution
Running a data platform such as Sentiance’s requires a lot of Cloud Computing resources. The bulk of it is taken up by data-processing, as opposed to data storage for instance. Over time, we have gotten quite good at utilizing resource optimization tools such as spot instances, savings plans, and auto-scaling to keep costs under control.
Performing data processing on the smartphone directly, where and while the data is being collected, reduces the overall cloud-based server footprint significantly. Of course, performing more data processing on the smartphone can have an impact on battery drain, which brings us to the next motivation.
Improvements in smartphone hardware and software
Smartphone hardware has grown ever more powerful and advanced when it comes to (dedicated) CPUs, memory & storage access, and battery capacity. At the same time, software toolkits such as TensorFlow Lite allow for much smaller ML models, optimized for use on mobile phones. Combined with our own data management optimizations, these improvements have allowed us to already bring several data processing components to the SDK without visible impact to battery life, when compared to our existing data collection-focused SDK.
Creating new integration options and supporting new use cases
Having a data platform where processing occurs in the Cloud adds additional latency to the process of extracting insights from the data. This latency can start to add up significantly when users are located in areas with poor network connectivity.
With edge computing, when data processing occurs where the data is collected, i.e. in the Mobile SDK, this additional latency is eliminated. Processing can happen as soon as data is collected and the results can immediately be delivered to the app from the SDK, which is often where the results are needed. New use cases that require such immediate access to contextual insights can hereby be better supported. Sentiance is currently partnering with leaders in automotive safety to build mobile-based crash detection solutions where every minute can literally save lives.
In short, having data processing capabilities in the Mobile SDK allows for insights to be provided promptly even with intermittent network connectivity. As long as the relevant geospatial data has been synced up in advance, even areas without network connectivity can be supported.
Capitalizing on our successes
Having an existing data platform and processing components in place, meant that we did not have to start from scratch for our Mobile SDK implementation. Having large amounts of training data, a reproducible ML Model training pipeline, and a multi-disciplinary team of data scientists, data engineers, and mobile engineers already in-house, gave us a massive head start.
Learning from our mistakes
On the other hand, bringing this existing functionality to the Mobile SDK also allowed us to have a fresh look at our data management, and streamline several aspects of it.
For example, for the Cloud backend, as it grew over the last years, some functionalities ended up being spread out over multiple components. Transport mode classification is mostly determined from a single microservice, however other microservices can still finetune that result at different time intervals. Updating our transport mode classification technology for use in the SDK let us bring all these learnings together into a single responsibility component. Hereby, making it easier to maintain the classifier, as transport modes are only determined in a single location, and easier to use its outputs, as transport modes can only come from one component.
How did we execute it?
Creating high-quality, production-ready AI products is an intensive process requiring the capabilities of a diverse group of technical people. In order to bootstrap this effort, we brought together a multidisciplinary “On-Device” team to lay the groundwork for the implementation. This team consists of Data Scientists, Machine Learning Engineers, Mobile Engineers, and Data Engineers who all have their own domain of expertise.
The Sentiance SDK Architecture
The Sentiance SDK uses an event bus approach, as illustrated in Figure 2, to decouple its different functionalities. Messages on this bus can be data messages, such as a location fix, or control messages, e.g. to stop data collection. Each functionality has its own isolated component that subscribes to the event bus for those messages it is built to handle, and can publish new messages on the event bus that might be needed by other components.
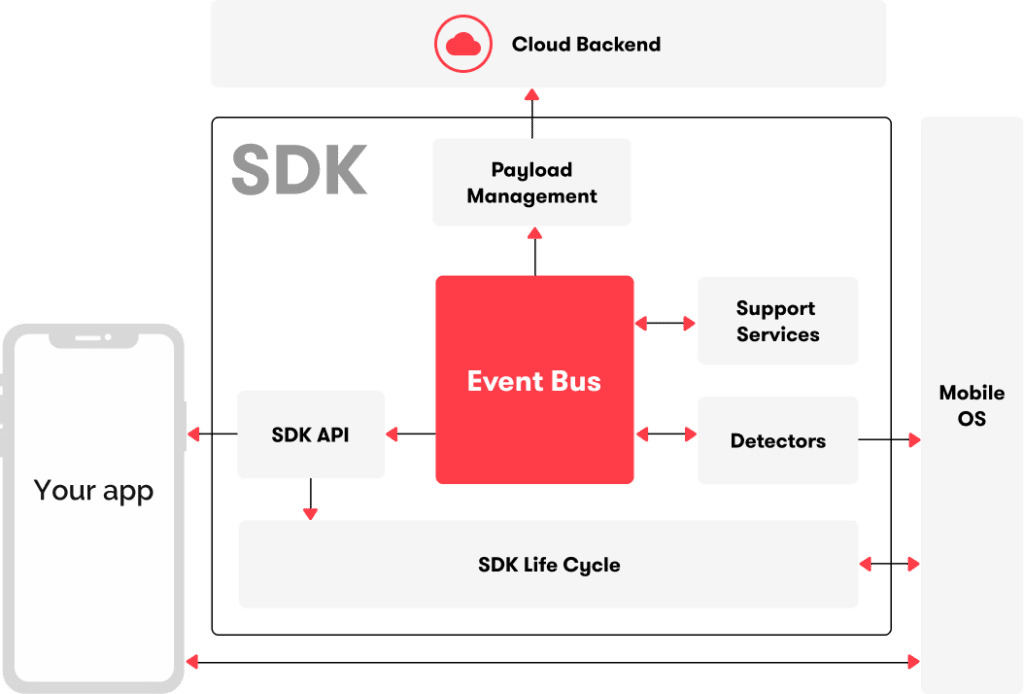
Figure 2: Event bus architecture of the Sentiance SDK
This architecture allows, for instance, to separate the logic of how data is collected from the different smartphone sensors into different Detector modules. These all listen to the control messages on the event bus to determine when they should (de)activate. Another module then is responsible for packaging and transferring payloads with collected sensor data to the Cloud backend. It maintains networking and retry logic that can operate on different schedules than the detector modules.
Apart from the separation of concerns that an event bus provides, it also allows us to log the messages that flow through the event bus for inspection and debugging purposes. It also provides us with a view of the inner workings of the SDK as it is operating during the QA process or even from live SDKs.
Adding data processing into the mix
To extend the SDK with new data processing capabilities, we had to address several complexities.
Translating ML Models to a mobile-friendly format
Over time we have built a rich collection of models that contribute to the core intelligence of the Sentiance platform, such as transport mode classification, driver-passenger detection, venue mapping and event prediction. Our existing models are mostly created in Python, but to run them on smartphones, they need to be compatible with Java/Kotlin (Android) and Objective-C/Swift (iOS). Disk space and memory come at a premium on mobile and we’d need to run several models, so they also have to be as small as possible.
We turned to TensorFlow Lite for our ML models as a way to train them offline in the Cloud yet with the ability to run the same model artefact on both Android and iOS, or in the Cloud .
Apart from the write-once, run-anywhere benefit, it also provided a way for cleanly assigning responsibilities in the development process. When a new model is released by the Machine Learning Engineers, it comes with a test harness that Mobile Engineers can use to verify outcomes for their own Android and iOS TensorFlow Lite runtimes during integration into the SDK codebase.
Geospatial data access
One of the primary ways that Sentiance enriches the raw data of mobile sensors is by incorporating geospatial data. As we want to provide insights regardless of where on earth users are located or travelling, we work with large datasets that cover the entire planet. As long as data processing happens in the Cloud, it is easy enough to launch a couple of bigger compute instances or databases to serve this geospatial information.
Bringing our brand of data processing to the SDK thus also meant providing it with access to geospatial data. Bringing a full planet-size dataset to the phone is, of course, not feasible. Requesting geospatial data at the moment it is needed from a backend, is issue-prone. Intermittent network connectivity might delay how long it takes the necessary data to reach the algorithms. Furthermore, if these requests are too fine-grained, they still risk exposing user location data.
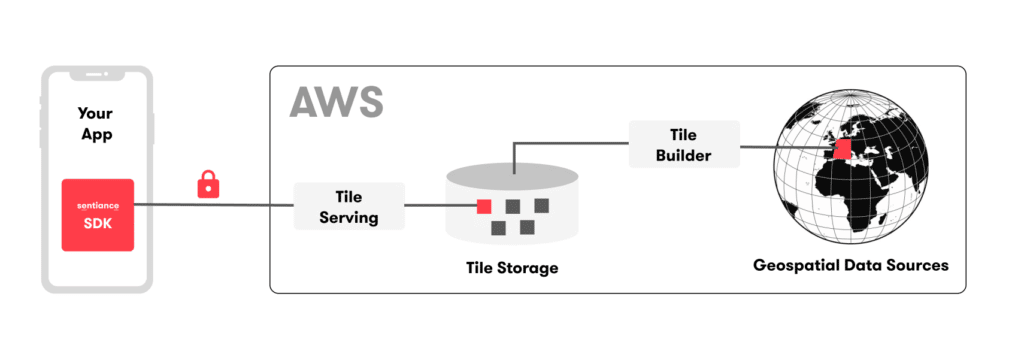
Figure 3: Serving geospatial tiles
As a solution, we turned to a tile server approach, see Figure 3. This is similar to how online mapping tools work, but instead of the tile being a pre-rendered image for visualization, our tiles are represented as precomputed, binary files containing all relevant geospatial data at a specific zoom level for use in the on-device algorithms. Whenever the end-user enters a region for which no geospatial data is present on the SDK yet, the SDK will compute an identifier (a quad key) with which it can request the corresponding tile and store it locally. On the one hand, these tiles have been created such that they are large enough that knowing which tiles a specific user has requested does not constitute personal data. On the other hand, we ensure that the physical size of tiles is not prohibitive for transmission to the smartphone. Our aim is to keep the individual tile size below 10 MB for anything but the densest of areas. Once downloaded by the SDK, the tile contents can be reused for any subsequent algorithmic need, until it expires, at which point an updated version of the tile is requested.
Integrating the functionality in the SDK
The “On-Device” Team was designed to tackle these new concerns as one closely-knit, dedicated team focused on a singular goal.
Data Scientists and Machine Learning Engineers translated models to TensorFlow Lite and set up reproducible training pipelines on top of MLFlow. Here, the benefits of the Event Bus architecture appear. These new ML-based components can be plugged into the SDK without having to refactor our existing code. They can utilize the existing data and control messages to manage their activation, and at the same time safely publish new messages without disrupting any of the existing functionality.
Data Engineers within the “On-Device” Team set out to develop the tile Server implementation. They set up pipelines for cleaning, filtering, and serializing geospatial datasets as part of the tile building process. They created secure and anonymized tile retrieval access and implemented the necessary monitoring and reporting to track usage. Mobile Engineers within the team implemented tile management within the SDK, hereby using their experience in payload management to create a robust tile retrieval and caching mechanism.
Last but not least, the Mobile Engineers also created a new testing and QA mobile app that saw regular updates as new functionality was implemented. Apart from its obvious use to validate the correctness and battery usage of the on-device data processing components that were being created, it gave the whole of the company a view into the progress of this project. Feedback controls within the app provided a much-needed verification capability but also allowed every colleague to be a contributor to this new direction we are moving into.
When will it be available?
We released in early 2021 a new version of our crash detection technology that makes use of the new SDK-based data processing pipelines as described above. At the same time, we have been working on many of the other established functionalities of the Sentiance Platform as well.
This intensive development and internal testing culminate into an official release of the Sentiance SDK Q3 2021 with the first versions of our transport mode classification, venue mapping, and home/work detection technology fully executed directly on the smartphone, thereby turning it into a true edge computing implementation. At the same time, it will also see the introduction of a new API as part of the Sentiance SDK that provides apps direct access to the insights being created. This way, no personal data needs to leave the user's phone to bring the best contextual app experience. We will open up to external testing in the near future, so leave your details if you want to become part of the test group.
We plan to launch Moments, Segments, and Predictions before the end of the year as well as providing additional feature updates and accuracy improvements.
Sentiance is constantly looking for innovative ways to take our platform to the next level with the latest technology. The goal of switching to on-device data processing is to enable more use cases and protect end-users' privacy even more. If you are interested in learning more, get in touch and let's discuss how this can benefit your use case.


